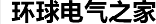發布日期:2022-04-18 點擊率:117
關鍵詞: 內核架構
摘要:在整個嵌入式領域,“更多內核”已經成為設計趨勢,一些硬件架構可以提供數十個內核,有些架構中的內核甚至多達上千個。然而,多內核設計在軟件方面仍存在諸多挑戰,在不同架構間進行應用程序的移植并不容易。
在低端嵌入式領域,單內核解決方案仍然存在。通過采用速度更快或帶寬更寬的處理器仍有可能提升系統的功能和性能曲線。在高端領域,多內核是必然的發展方向。這正是雙精度浮點算法經常出現并在超級計算機中長盛不衰的原因。事實上,臺式機和機架安裝系統(比如Nvidia的產品)正在將這種處理能力普及化。
在討論軟件和多內核架構時經常提及的另一個問題是虛擬化。并不是所有多內核平臺都支持虛擬化,但虛擬化確實能帶來更好的機會。雖然虛擬化使得硬件設計面臨更多的挑戰,但它通常能簡化軟件和應用管理。
SMP服務器
Xeon Nehalem-EX是Intel公司提供的頂級8內核對稱多處理(SMP)平臺。像8芯片、64內核系統這樣的多芯片解決方案,通常采用高速 QuickPath點到點互連技術將處理器和外設控制器鏈接在一起(圖1)。使用過帶HyperTransport鏈路的AMD Opteron處理器的工程師,對這種架構非常熟悉。在這兩種情況下,最簡單的配置是單個處理器通過單條高速鏈路鏈接到單個外設控制器。
除了提供分布式內存子系統外,Intel和AMD還實現了連貫緩沖非統一內存尋址(ccNUMA)技術。每個處理器芯片都有自己的內存控制器以及一級、二級和三級緩存。任何芯片都可以使用高速鏈路訪問其它任何芯片中的內存。當然,離請求者越遠的數據訪問時間越長。這些高速鏈路也被用于消費設備,但只有到 I/O中心的單條鏈路是必需的。換句話說,在共享內存訪問時服務器將在處理器芯片間產生顯著的流量。芯片至芯片流量和緩存管理是高效操作的關鍵。
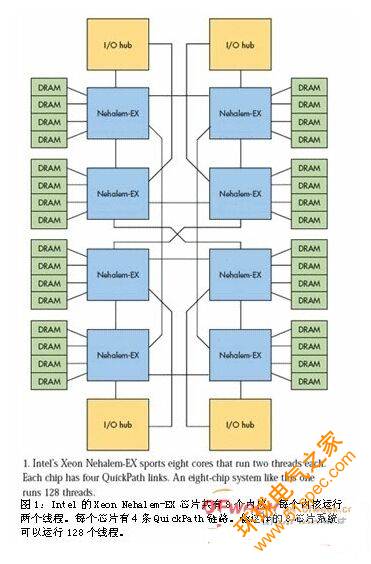
HT Assist是AMD最新推出的Istanbul Opteron處理器的一個重要功能,它通過優化內存請求和響應過程來盡量減少相關事務處理的數量,進而釋放出大量帶寬用于處理其它業務(圖2)。HT Assist實際上會跟蹤數據在內核和緩存間的移動,允許請求得到具有所需數據的最近內核的服務。
最壞的情況是擁有片外存儲器空間的芯片必須從片外存儲器訪問數據;最好的情況是發現數據正好位于運行著需要這個數據的線程的芯片緩存中;中間情況是內核從相鄰芯片的緩存中獲取數據。使用虛擬化和緩存技術后系統將變得更加復雜,并導致數據延時更加難以確定。這在確定性嵌入式應用中可能是個問題,但在大多數服務器應用中問題并不十分明顯,因為這種情況下的速度比精細的確定性更加重要。
編程人員現在都在使用這些平臺,因為它們能大大簡化編程任務。同樣,應用程序可以使用越來越多的內核,前提是應用程序可高效地利用充足的線程。高效使用多內核系統并不像表面看起來那么容易。緩存大小和應用程序工作數據集中的參考位置會影響特定算法的運行效果。
AMP應用處理器
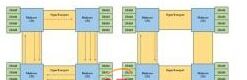
對稱處理(SMP)架構對許多嵌入式應用來說非常有用,但非對稱多處理(AMP)也有它的用武之地。AMP配置在很多地方都可以看到,從TI的OMAP(開放多媒體應用平臺)到飛思卡爾的P4080 QorIQ都有AMP的身影(圖3)。
TI的OMAP 44xx平臺整合了ARM Cortex-A9、PowerVR SGX 540 GPU、C64x DSP和圖像信號處理器。每個內核有專門的功能,處理器之間的通信不是對稱的。OMAP只工作在AMP模式,而P4080的內核是SMP系統,但也能夠將內核劃分為AMP模式。8內核芯片可以像8個獨立內核那樣運行,在許多配置中也可以聯合起來使用(如一對雙內核SMP子系統,或四個單內核子系統)。
OMAP和P4080在高層架構的主要區別是OMAP功能是固定的,內核針對各自的事務做了優化。這將使編程容易得多,因為可以根據匹配功能將應用程序劃分到特定內核。
每個子系統的性能水平受架構的限制,但P4080可以調整劃分方案,雖然劃分通常是在系統啟動時完成的。系統設計師可以調整P4080中內核的分配,前提是有足夠多的內核。市場上也有內核數量較少的QorIQ平臺,因此可以選用更經濟的芯片。
IBM的Cell處理器填補了中間的空白。它采用了1個64位的Power內核和8個增效處理單元(SPE)。所有SPE都是相同的(每個有256KB的內存),它們工作在隔離狀態,這與上述討論的共享內存SMP系統有所不同。SPE內沒有緩存,也不支持虛擬內存。
對軟硬件設計來說,這種方式既有優點又有缺點。優點為是簡化了硬件實現,但從多個角度看都使軟件復雜化了。例如,內存管理受應用程序控制,就像內核間的通信一樣。數據在能夠操作之前必須要移進SPE的本地內存。完全開發Cell這樣的架構很花時間,因為它們有別于更傳統的SMP或AMP平臺。多年來在像索尼的PlayStation 3這樣的基于Cell的平臺上所作的軟件改進突顯了編程技術和經驗的變化。
GPU等專用處理器
改變編程技術是使用圖形處理單元(GPU)是否成功的關健。來自ATI和Nvidia等公司的GPU在單個芯片內有上百個內核,這些GPU可以被整合進多芯片解決方案,向開發人員提供上千個內核。例如,集成進1U機箱的4個Nvidia Tesla T10就可以提供960個內核(圖4)。
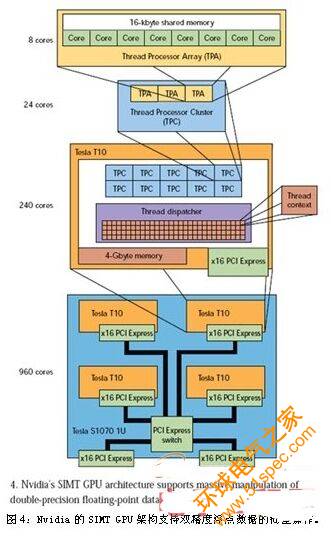
對Tesla或其它任何兼容的Nvidia GPU芯片進行編程都極具挑戰性,但類似Nvidia的CUDA這樣的架構或基于CUDA的運行時利用可以使工作變得更加輕松。部分挑戰來自于 Nvidia GPU的單指令、多線程(SIMT)架構。與許多高性能系統一樣,這種GPU喜歡處理數組數據。對許多應用來說這是不錯的選擇,但并非都是這樣,這正是 GPU經常要與多內核CPU匹配的原因之一。
本文引用地址:http://www.eepw.com.cn/article/201609/303646.htm
另一種并行編程架構,CUDA和OpenCL(開放計算語言),則完全匹配GPU方法(使用與主處理器分開的存儲器)。這意味著數據在能被操作之前必須從一個地方移動到另一個地方。C編程語言有一定擴展,但也有限制。例如,它是自由遞歸的,不支持函數指針。其中一些限制源自SIMT方法。
許多應用程序使用CUDA,但與傳統SMP平臺相比,性能增益有很大的變化,從2倍到100倍不等。造成這種變化的原因是,線程以32為組運行時的效率最高。分支不影響性能,前提是32線程組在同一分支內。
像GPU這樣的專用處理器,其采用的方案是同時提供圖形和多內核處理。另外一種方案是使用許多傳統內核,如Intel的Larrabee(圖5)。Larrabee使用專門針對矢量處理優化過的x86兼容內核。
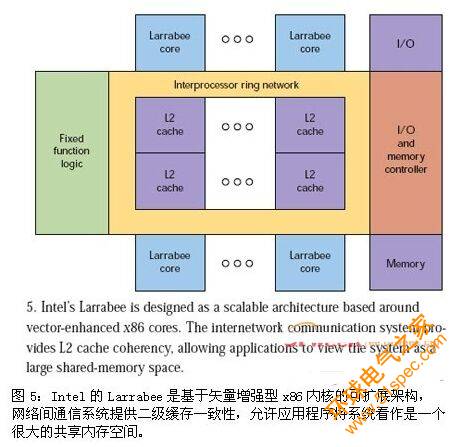
從某種角度看,Larrabee有點類似于IBM的Cell處理器。Larrabee內核只有32KB的一級緩存和256KB的二級緩存可以訪問。如果數據不在緩存中,必須從內存控制器或系統中的另一個緩存中申請,然后數據被放進內核的緩存中,再由應用程序繼續處理。
環形總線用于內核和控制器之間的通信。IBM的Cell單元互連總線(EIB)也是一種環形總線,連接著 SPE和內存控制器以及外設接口。從編程角度看,Larabee的緩存和Cell的SRAM有很大的差異。誠然,對編程人員來說,Larrabee看起來更像是一組連貫緩存的x86處理器。由于其GPU定位,編程人員可以充分利用它對DirectX和OpenGL的支持。
多內核聯網
多內核芯片也是網絡基礎設施中的常見元件。處理10Gps的網絡對多內核芯片來說本身就是很大的挑戰。分析和處理來自線速網絡連接的數據需要大量的處理資源。
Netronome的NFP-3200網絡流量處理器包含40個1.4GHz的內核,每個內核可以運行8個線程,因此1個芯片總共可提供320個基于硬件的線程。這個數量級與GPU相同,但這些處理器主要用于數據包處理。
與IBM的Cell一樣,NFP-3200也有一個主CPU型控制器,而且是一個ARM11內核。NFP-3200的40個內核也叫做微引擎,兼容 Intel的IXP28xx架構,主要用于網絡處理。這種兼容性很重要,因為大量代碼是針對這種架構開發的。較老的芯片具有較少的內核,因此在某種意義上 NFP-3200提供的是相同解決方案。
當然,為解決問題而簡單地采用更多的內核只是其中一種措施。Netronome作了大量改進,例如支持TCP任務卸載的增強型微模塊。互連速度也更高了,內核之間的運行速度高達44Gbps。
Netronome芯片擁有大量的專用處理器,其中包括了用于處理各種安全協議的加密系統。Netronome的PCI Express接口支持x86處理器經常使用的I/O虛擬化功能。它能被移動到NFP-3200旁邊,而不是被另外一條網絡鏈路隔開。
與其它多內核芯片相比,編程NFP-3200通常沒有太大問題,因為針對IXP28xx系列有大量現成代碼。另外,Netronome提供庫,這使得網絡處理應用程序的創建更像是模塊的堆疊。
Cavium的Octeon II是一種更傳統的SMP多內核設計,有2到6個64位 MIPS64內核,它們通過一個交叉開關相連。與Netronome芯片一樣,Octeon II是針對網絡和存儲設備設計的。
Octeon II還有一個RAID 5/6加速器以及用于數據包檢查的正則表達式超有限時序機(HFA)。編程Octeon II與編程大多數SMP系統相仿。Octeon II可以運行諸如Linux的操作系統。
其它多內核架構
采用更激進的多內核架構會增加編程事務,但它能為開發人員開啟利用新架構的機會。IntellaSys的SeaFORTH 40C18就屬于這種類型(圖6)。它本身的編程語言是VentrueForth,指令長度實際上是5位,4個指令可以壓縮為單個18位的字(一個指令只有3位長)。40C18有40個內核,它們有相同的處理單元,并且都有64個字的RAM和64個字的ROM。
與具有更多存儲空間的芯片(如Intel的Larrabee或IBM的Cell)相比,對40C18進行編程顯然有很大的區別。40C18內核的功耗不到9mW,而其它兩種芯片在沒有大散熱器或風扇的情況下都無法正常工作。40C18設計用于嵌入式甚至移動應用。
對大多數開發人員來說,對40C18進行編程將是不同的體驗,這不僅因為Forth是編程語言。每個內核的小內存容量和矩陣互連改變了程序設計方法。內核通常運行將數據傳送到一個或多個相鄰內核的小型函數,因此協同編程將是大勢所趨。
即使外部存儲器訪問也要求三個內核一起工作,當有許多內核可以一起工作時這種方法很管用。40C18還有一種獨特的能力,它能將4個指令組成的小程序用一個字發送給相鄰內核執行,因此就有足夠的空間執行塊傳送。
XMOS公司的XS1-G4是一種基于32位整數Xcores的有趣混合產品。每個Xcore可以處理大量不同的線程,同時還有一個基于硬件的事件系統幫助XMOS的軟外設。與40C18一樣,XS1-G4可以在I/O端口上等待。區別是XS1-G4處理多個線程,而IntellaSys芯片處理單個線程。
開發人員可以使用C語言的擴展版本XC發揮XMOS硬件的最大功效。C語言擴展提供了到硬件支持的快捷路徑,其中也包括 Xlinks。Xlinks連接芯片中的4個內核,并提供4個片外鏈路,因此可以連接多個芯片。芯片內部使用一個開關用于Xlink連接,但硬件和軟件為處理器間通信提供統一接口。
每個內核有64KB的內存,這個容量比40C18大,但比本文提到的一些更高性能的芯片的內存容量小。同樣,對大部分應用代碼來說這個容量是足夠用的,并且允許使用更傳統的線程方法進行編程。針對XMOS芯片的大部分編程工作很可能用傳統的C或C++完成,而不是用XC,后者更傾向用于通信和外設處理。
XS1-G4不會向雙精度浮點GPU或其它高端系統提出挑戰,但它的整數和定點DSP支持使得它適用于其它許多音頻和視頻處理功能。鏈接好的XMOS芯片早已在內部用來驅動多個大屏幕LCD。
多內核架構還將繼續保持高速發展。高效地對這些內核進行編程和選擇合適的產品并不容易,但它會變得越來越普及,即使是對嵌入式開發人員而言。傳統應用程序將不斷地移植到匹配現有主機的架構上。當應用程序被重新設計或從頭創建時,也許會有更好的方案產生。
下一篇: PLC、DCS、FCS三大控
上一篇: 索爾維全系列Solef?PV

型號:普通型鋼絲螺套
價格:面議
庫存:10
訂貨號:006

型號:成套鋼絲螺套安裝工具
價格:面議
庫存:10
訂貨號:01